What’s new?
In a paper published in 2022, researchers from DeepMind showed how we can extrapolate the ideal model size (N) and pre-training dataset size (D) to achieve thelowest possible validation loss given a predefined compute budget.
How does it works?
The team at DeepMind did run over 400 experiments with models ranging from 0.5B to 17B parameters and different dataset sizes. Critically, they chose these quantities while keeping fixed computing budgets, in order to later fit three models to estimate the optimal values for N and D to minimize the validation loss. The team used three approaches to estimating the optimal value for those quantities. All three approaches converged to very similar solutions, where doubling the size of the model should require doubling also the size of the training dataset.

To prove the validity of their findings, they trained a new LLM, named Chinchilla (70B parameters, 1.4T tokens), which was able to outperform much larger models like GPT-3 (175B parameters, 300B tokens) and Gopher (280B parameters, 300B tokens) in a series of benchmarks.
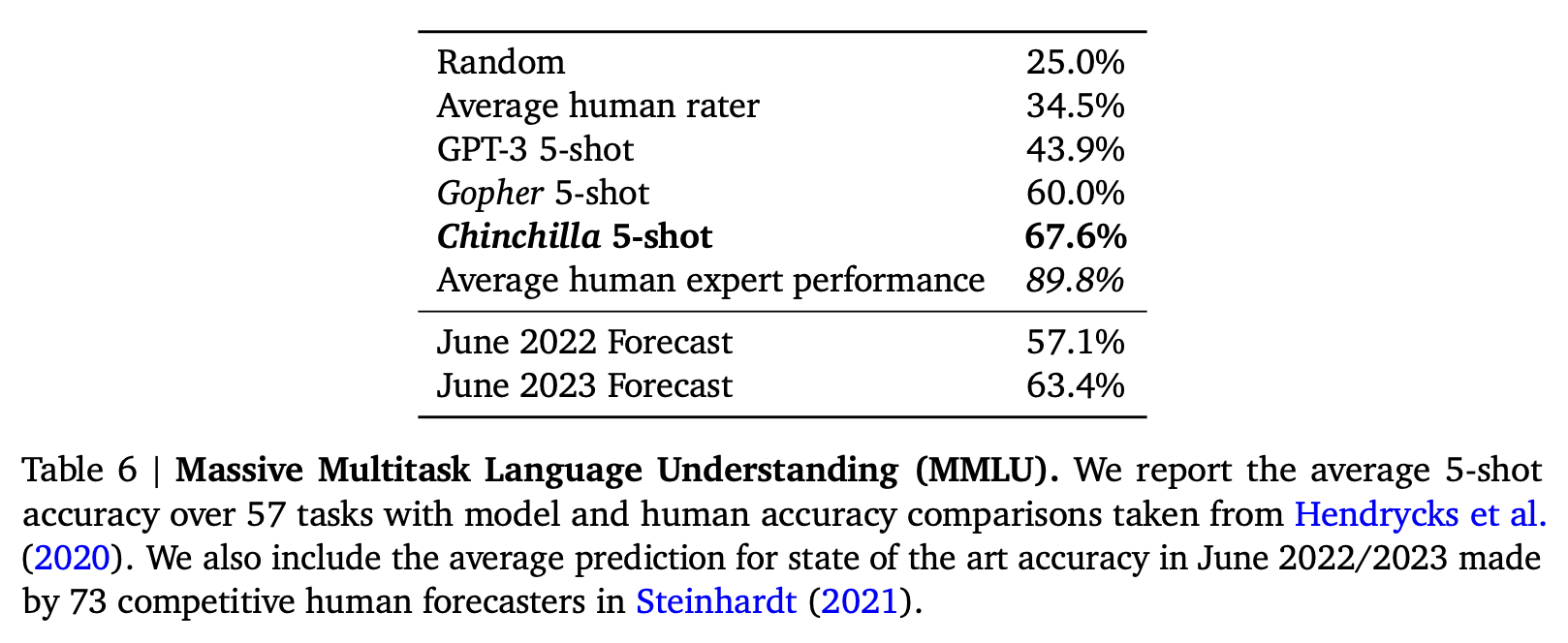
Why it matters?
This work shows how LLMs trained in the past few years are not compute optimal, and could have achieved better results by selecting a smaller model size and much large pre-training dataset size. This is a significant results because it shows that much smaller models, that are cheaper to train and use at inference time, can be competitive and even outperform much larger models trained on less data.
What do we think?
Compute optimal models are not necessarily the best models. As shown in recent work from XXX, given a fixed model size, training a model with even more tokens than what suggested in this paper, can lead to an even better model, while suffering minimal computing overhead. That said, the scaling law published by DeepMind can give us a good starting point to select a smaller model and dataset size to iterate fast, before confidently scale the model and dataset size